
Удаление повторяющихся строк из текстового файла можно выполнить из командной строки Linux.
Такая задача может быть более распространенной и необходимой, чем вы думаете.
Чаще всего это может быть полезно при работе с файлами логов.
Зачастую файлы логов повторяют одну и ту же информацию снова и снова, что делает практически невозможным просмотр файлов.
В этом руководстве мы покажем различные примеры из командной строки, которые вы можете использовать для удаления повторяющихся строк из текстового файла.
Попробуйте некоторые команды в своей системе и используйте ту, которая наиболее удобна для вашего сценария.
Эти примеры будут работать в любом дистрибутиве Linux при условии, что вы используете оболочку Bash.
В нашем примере сценария мы будем работать с файлом, который просто содержит имена различных дистрибутивов Linux.
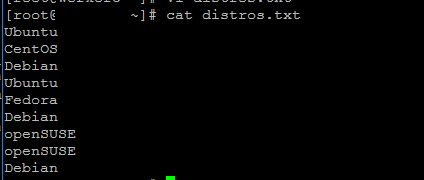
Это очень простой текстовый файл для примера, но на самом деле вы можете использовать эти методы для документов, содержащих даже тысячи повторяющихся строк.
Мы увидим, как удалить все дубликаты из этого файла, используя приведенные ниже примеры.
$ cat distros.txt Ubuntu CentOS Debian Ubuntu Fedora Debian openSUSE openSUSE Debian
Пример 1
$ sort distros.txt | uniq CentOS Debian Fedora openSUSE Ubuntu
Пример 2
Пример 3
$ sort distros.txt | uniq -c | sort -nr
3 Debian
2 Ubuntu
2 openSUSE
1 Fedora
1 CentOS